인터넷에서 정보를 찾을때 가장 많이 접속하는 사이트는 바로 네이버, 다음, 구글과 같은 검색 사이트 입니다.
이 검색 사이트는 웹이라는 네트워크에 출판된(publishing) 사이트의 HTML 문서를 검색엔진 로봇이 크롤링(Crawling)한 다음 검색 사이트의 자체 알고리즘으로 분석, 색인(Indexing) 하면 검색 사이트에서 방문자가 키워드로 검색시 검색 결과물로 색인한 페이지들을 보여주게 됩니다.
기업의 홈페이지, 블로그 서비스등 웹에 게시되는 모든 문서는 검색 엔진에 등록되어 검색 결과로 보여지기 까지 앞서 얘기한 같은 과정을 거치게 되는데 대부분의 문서는 웹에 공개되어 많은 방문자가 오길 기대하지만 반대로 공개되어 있는 문서이지만 검색 엔진에는 보여지고 싶지 않은 문서도 있을 것입니다.
이렇게 검색 엔진에 노출하고 싶은 문서와 그렇지 않은 문서를 검색엔진 로봇이 인식하게 설정해서 크롤링 범위를 지정하는 것이 바로 robots.txt 입니다.
robots.txt에서 설정한 접근 제어는 강제성이 없지만 네이버, 구글등 국내에서 가장 많이 사용하는 검색 엔진에서 robots.txt 설정을 권고하고 있는데 이는 robots.txt 규약을 준수한다는 뜻으로 검색 엔진 최적화(SEO)를 위해서라도 필수적으로 설정해야 합니다.
robots.txt 위치
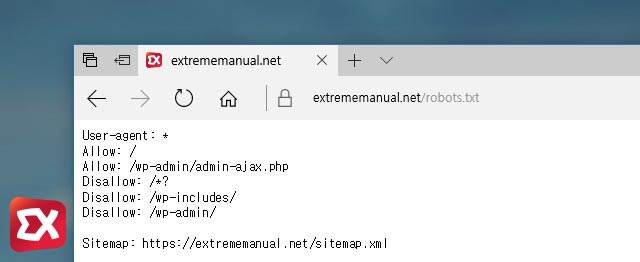
앞서 설명했듯이 검색엔진 로봇은 사이트(블로그)를 크롤링 할때 robots.txt 를 참고해 크롤링합니다.
작성한 robots.txt 파일은 루트 디렉토리에 위치해야 하며 robots 텍스트 문서 안에서 하위 디렉토리에 대한 검색엔진 로봇의 접근 제어를 설정해야 합니다.
robots.txt 작성 요령
예시
User-agent: * Allow: / Disallow: /admin/ Disallow: /private/ Disallow: /*.pdf$ sitemap: https://domain.com/sitemap.xml
robots.txt 파일의 내용 구성은 User-agent, Allow, Disallow로 구성되며 검색엔진 로봇별로 범위를 지정할 수 있습니다. 우선 각 문법에 대한 작성 요령은 위 예시와 같으며 다음과 같은 의미를 가지고 있습니다.
User-agent
User-agent 구문은 검색엔진 로봇 이름을 정의합니다. * 기호는 모든(All) 이란 의미를 가지며 모든 검색엔진 로봇에 대한 접근을 허용한다는 뜻입니다.
만일 특정 검색엔진 로봇(크롤링 봇)에 대해 색인 범위를 지정하고 싶다면 다음과 같이 설정할 수 있습니다.
User-agent: Yeti User-agent: Googlebot Allow: / User-agent: Googlebot-image Disallow : /
네이버 크롤링 봇 이름인 Yeti와 구글 크롤링 봇 이름인 Googlebot은 허용을, 구글 이미지 크롤링 봇(Googlebot-image)은 비허용으로 처리하는 예제입니다.
Allow
Allow 는 접근을 허용할 페이지를 설정하는데 / 는 최상위 페이지를 의미함으로 ‘사이트의 하위 문서를 크롤링해도 좋다’ 라는 의미입니다. 만일 Allow 선언되어있지 않다면 기본적으로 검색엔진 로봇은 허용(Allow)으로 간주합니다.
Disallow
Disallow 는 크롤링을 허용하지 않을 페이지를 선언합니다. 위 예시처럼 admin 하위 웹문서를 검색엔진에 노출시키지 않게 하고 싶은 경우에는 Disallow: /admin/ 과 같은 요령으로 지정하면 되겠습니다.
sitemap
사이트맵의 주소를 지정해서 크롤링 로봇이 따라갈수 있게(follow) 설정합니다.
패턴 규칙
패턴 규칙은 특정 확장자를 가진 파일을 검색엔진에 노출하고 싶지 않은 경우, 문서의 쿼리 결과값을 선언할때 유용하며 다음과 같은 요령으로 작성합니다.
Disallow: /image*/ Disallow: /*.pdf$ Disallow: /*.hwp$ Disallow: /*.doc$
Disallow: /image*/ 는 image 로 시작하는 디렉토리에 대한 접근을 허용하지 않는다는 의미입니다. image-content, image-full 과 같은 디렉토리가 있다면 그 대상이 되겠죠.
만일 반대로 image로 끝나는 디렉토리의 접근 제어를 하고 싶다면 * 를 이름 앞에 두면 되겠습니다.
Disallow: /*.pdf$ 는 pdf로 끝나는 주소에 대한 접근을 허용하지 않는다는 의미입니다. 파일 이름이 어떻게 될지 알수 없으므로 * 로 모든 이름을 지정하고 주소 끝을 알리는 $ 를 선언합니다.
robots.txt 파일을 만들지 않은 경우?
robots.txt 파일이 루트 디렉토리에 위치하지 않은 경우 기본적으로 허용(Allow)로 인식해 모든 페이지를 크롤링합니다. robots.txt 내용에 Allow 구문이 없는 경우 기본적으로 모든 페이지 크롤링을 허용하는 것과 같은 맥락입니다.



4개 댓글. Leave new
안녕하세요. 올려주신 글 잘 읽었습니다.
티스토리에서 robots.txt 설정에 대해 질문이 있어 댓글 남깁니다.
티스토리는 서버레벨에서 일괄적으로 robots.txt가 적용되며 사용자가 컨트롤 할 수 없습니다.
네 알겠습니다.
답변해주셔서 감사합니다~
Very nice article. Thanks for explaining about robots.txt in a simple manner.